How we benchmark AI agents before production
When you open a Messy Virgo news digest, you are not looking at raw RSS feeds or a chatbot answer pasted into a product. You are looking at the output of a full AI-assisted process: sources are ingested, items are deduplicated, relevance is carried forward across time, macro meaning is interpreted, scores are computed, and guardrails enforce what we are willing to show.
This post is about the layer above normal software testing.
We still test the software in the usual ways: unit tests, integration tests, smoke runs, code review, AI-assisted review, human review when needed, and build pipeline checks. Those controls prove the code path is safe to ship.
They do not answer a different question: which model and agent configuration is the best operational fit for this task once real state, real context, and real guardrails are involved?
That is what these evals are for.
The question is operational fit
It is easy to ask several models the same prompt and compare which answer sounds better. That can be useful early in development, but it is not enough for a production system.
In Messy Virgo, the model is only one part of the product. A useful benchmark has to test the model inside the job it is actually expected to perform:
- Can it use the prepared context correctly?
- Does it preserve memory across cycles?
- Does it respect the output contract without constant repair?
- Does it surface the important signal without flooding the digest?
- Does it finish within the latency and reliability budget?
The winner is not the model with the most impressive one-off response. The winner is the configuration that produces the most reliable product output for the specific component.
We benchmark the process, not a prompt in isolation
It is easy to demo an LLM on a static JSON file and declare victory. Production is different. Our context news component, for example, runs like this:
- Integration — Pull recent items from multiple sources (market news APIs, crypto RSS, macro feeds such as Fed press releases).
- Ingestion & deduplication — Normalize and collapse duplicates before anything is stored.
- Interpretation — An LLM curates what still matters: active vs monitoring, systemic catalysts, carry-forward rationale, horizons.
- Memory — The next sync sees prior state. Stories evolve, expire, or merge—not a blank slate every time.
- Scoring & guardrails — Domain scores, QA adjustments, caps, and deterministic repairs before a snapshot goes live.
We evaluate that entire chain on real infrastructure: queue, worker, database, validators—the same path production uses.
Swapping the model at the interpretation step is part of the benchmark, but it is not the whole benchmark. We are comparing model, prompt, tool context, memory behavior, and deterministic post-processing as one operating system.
Why this is different from software QA
Conventional tests catch broken code. They tell us whether a parser works, whether an API contract changed, whether a worker can complete a happy path, and whether the site or app still builds.
AI evals catch a different class of failure:
- The digest is technically valid but too noisy to use
- A major macro catalyst is present in the sources but absent from the output
- The model repeats the same story under several labels
- Memory carries stale narratives forward too aggressively
- Guardrails repair every cycle, which means the model is fighting the product contract
Both layers matter. Software QA protects the implementation. Full-pipeline AI benchmarking protects the judgment layer.
Why multiple cycles matter
A single run only tells you cold-start behavior. Real news updates every few hours. Memory is where pipelines break:
- The same story reappears under a new headline
- A macro catalyst drops out after the second sync
- Carry-forward logic fights the model and triggers endless “repairs”
- A run completes once, then times out or fails validation on the next pass
So we run three consecutive sync cycles per configuration. Cycle 1 is day zero. Cycles 2 and 3 simulate ongoing operation. If the process only works on a fresh database, it is not ready.
What “good” means (quality gates)
We define pass/fail criteria for the output of the pipeline, not for model eloquence:
| Gate | What we look for |
|---|---|
| No duplicate topics | The same story does not appear twice under different labels |
| Bounded digest | Active items stay within a sensible cap: signal, not noise |
| Systemic recall | Major macro or geopolitical catalysts in the sources appear in the digest |
| Low repair friction | Guardrails enforce policy instead of rewriting the model every cycle |
| Runtime stability | Runs finish within the expected budget without repeated retries or failed snapshots |
We also record failures that stop the pipeline entirely: validation errors, timeouts, queue retries.
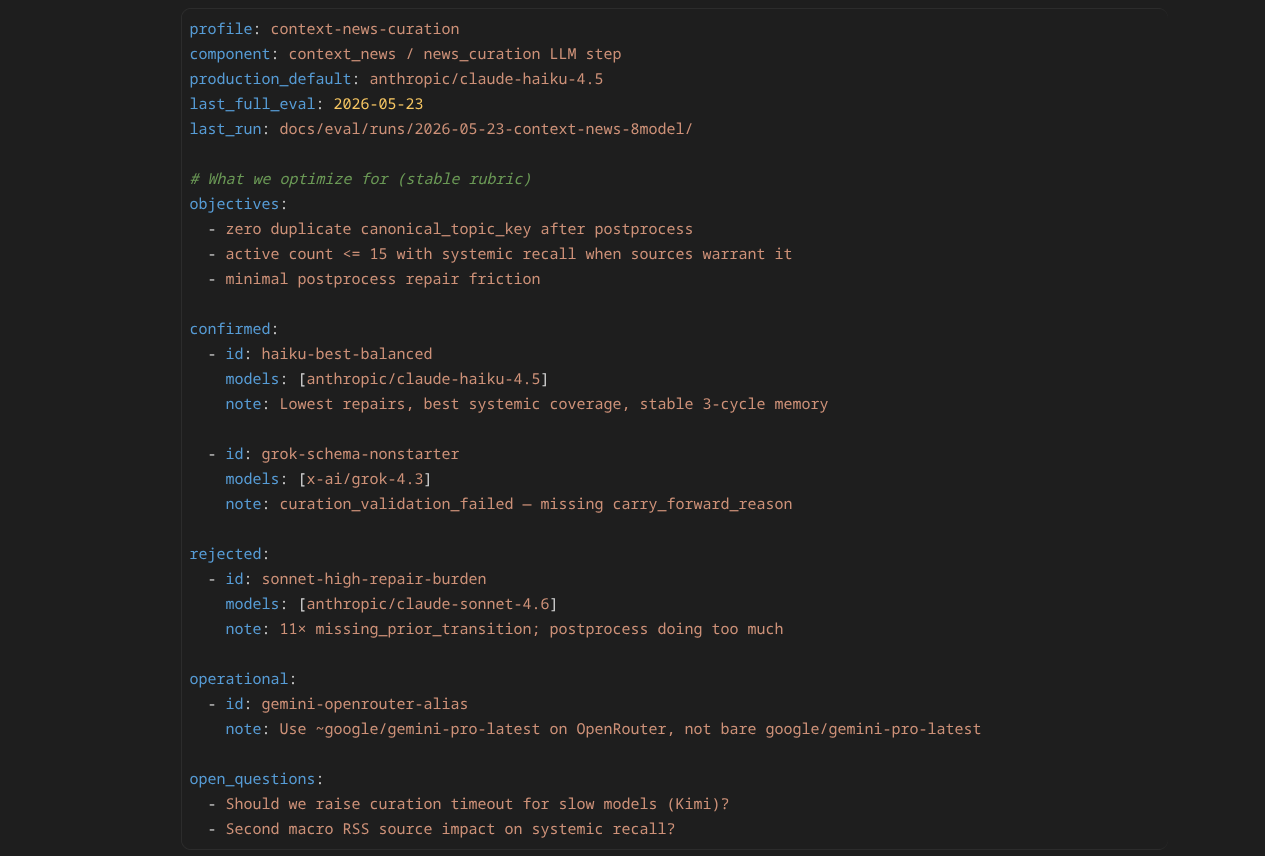
Example: context news eval (May 2026)
After strengthening prompts and post-processing (v1.7.0), we ran a full 8-configuration eval on the context news pipeline. Each configuration used the same integrations, same guardrails, same three-cycle protocol—the interpretation model was the variable under comparison.
The runner resets memory between configurations, executes three real syncs through the worker, exports snapshot metrics per cycle, and records findings for the team. This is not a generic public leaderboard. It is a component-specific benchmark for the context news job inside Messy Virgo.
Results after three cycles
- Claude Haiku 4.5 — 7 active stories, 1 repair, 3 systemic topics. Best balanced — production default.
- GPT 5.4 mini — 5 active stories, 2 repairs, 2 systemic topics. Viable, with a tighter digest.
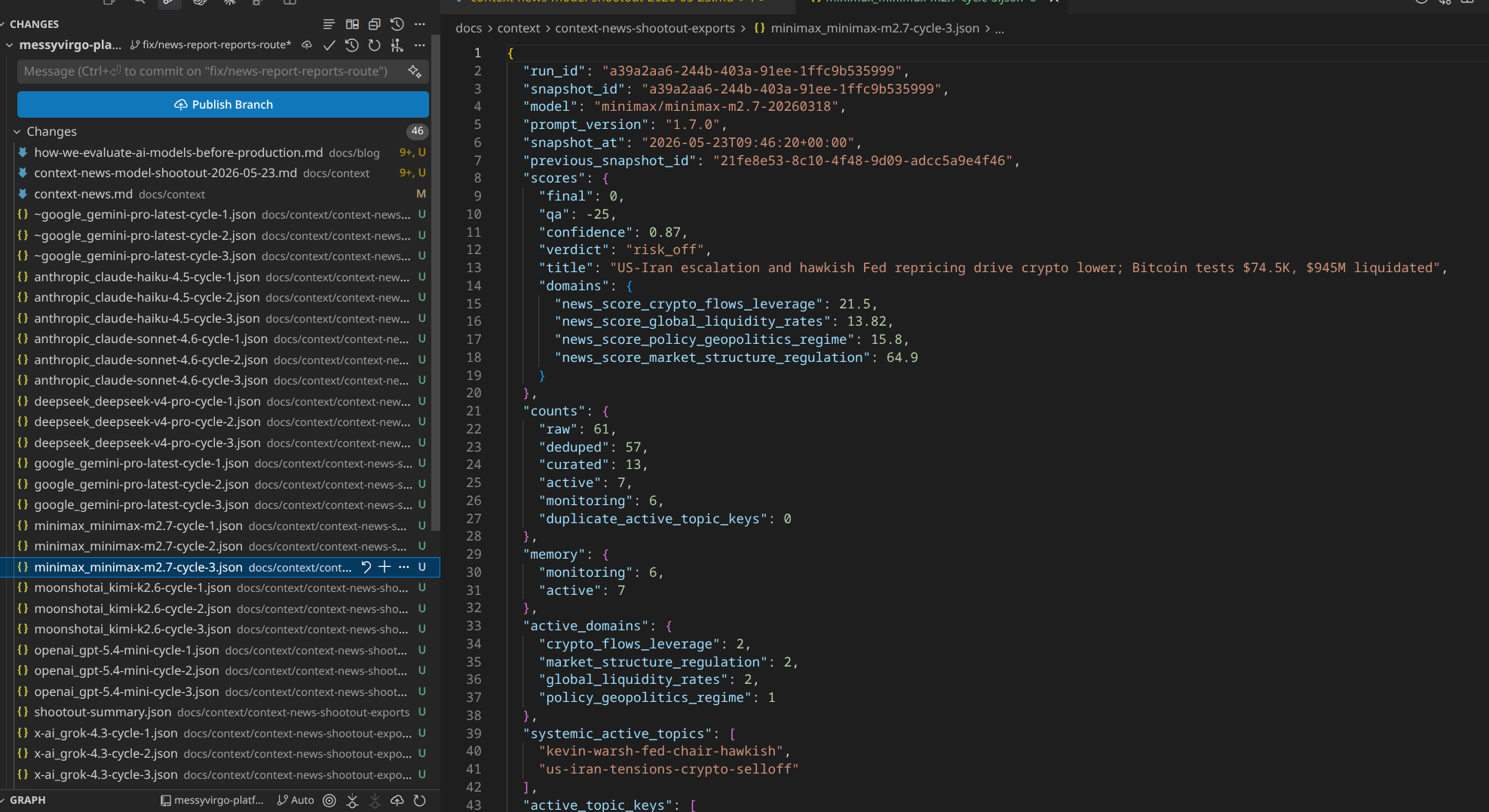
- MiniMax M2.7 — 7 active stories, 2 repairs, 2 systemic topics. Viable after a first-cycle failure, then stable.
- Gemini Pro Latest — 5 active stories, 4 repairs, 2 systemic topics. Viable and stable, with slightly more repairs.
- DeepSeek V4 Pro — 6 active stories, 7 repairs, 2 systemic topics. Passed the gates, but with noisier repairs.
- Claude Sonnet 4.6 — 5 active stories, 13 repairs, 1 systemic topic. Passed the gates, but with a heavy correction load.
- Kimi K2.6 — 6 active stories, 5 repairs, 1 systemic topic. Partial result: completed only cycle 1.
- Grok 4.3 — no valid result. The pipeline failed validation every cycle.
Haiku remained the production default for this component—not because it “won a benchmark” in the abstract, but because the full process stayed stable: fewest repairs on cycle 3, strongest systemic coverage (Fed path, Fed chair, geopolitical catalysts), and clean behavior across all three memory cycles.
Sonnet produced readable headlines but the pipeline had to fix thirteen structural issues on cycle 3 alone. Grok never produced a valid snapshot. Kimi completed a cold start but could not finish the memory stress test within our latency budget.
Those outcomes are about operational fit, not chat quality.
How this helps us choose models
We do not assume one model should run everything. The best model for context news may not be the best model for council deliberation, lens synthesis, token resolution, or report writing.
Each AI-powered component needs its own eval profile:
- Fixed inputs and realistic fixtures
- A repeatable run protocol
- Clear product gates
- A current production default to beat
- Artifacts that explain why the default changed, or why it did not
That gives us a practical way to keep improving as new models appear. A new model earns its place by improving the actual workflow, not by being newer, larger, or better marketed.
Guardrails are part of the benchmark
The interpreter is one step. Deterministic post-processing enforces caps, merges duplicate topics, demotes stale systemic tags, and validates schema. That is intentional: the model proposes; the platform commits.
Our evals measure how hard the platform has to work after interpretation. A configuration that constantly needs correction is expensive, brittle, and risky—even if individual summaries sound good.
A repeatable pattern for other components
We are formalizing this as an internal eval framework: profiles for each major component, run artifacts, and a findings registry so learnings accumulate instead of living in one-off spreadsheets.
The same shape applies elsewhere:
- Council workflows — evidence assembly, policy gates, multi-agent deliberation, certification
- Lens outputs — token resolution through scoring, with consistency checks on fixed inputs
Different components, different gates. Same principle: test the full process on realistic fixtures, across cycles where state matters, document what shipped and why.
The bottom line
We do not ship “an AI model.” We ship an AI-assisted operating process—integration, processing, interpretation, memory, and guardrails—that runs on a schedule and lands in the product.
Normal software testing proves the implementation is safe. Full-pipeline AI benchmarking tells us whether the model and agent configuration is the right fit for the job.
Before a component goes live or a default changes, we run the process for real, measure the outcomes that matter to users, and write down what we learned. The model is one knob. Process quality is the product.